Data Analytics
![]()
Welcome! You have just launched a live example of an Jupyter Notebook. The notebook is an open-source, interactive computing environment that lets you combine live code, narrative text, mathematics, plots and rich media in one document. Notebook documents provide a complete reproducible record of a computation and its results and can be shared with colleagues (through, for example, email, web-hosting services such as GitHub, Dropbox, and nbviewer).
Adapted from the Nature IPython Interactive Notebook demo.
You can edit anything in this temporary demonstration notebook, including the text you are reading.
Jupyter is a way of computing and doing data science right on your browser. It gives you a Notebook — this document we’re looking at now.
A Jupyter Notebook can contain: formatted text, images, videos, pretty math equations, and executable computer code. By “executable,” we mean that you run the bits of code, right in the document, and get some output displayed for you. This interactive way of computing, mixed with the text, allows you to tell a story (even to yourself) with extra powers!
Jupyter Notebook App
If you are not running Jupyter locally on your computer (or on some cloud-hosted service), and want to see what the Jupyter Notebook App looks like, you can always try it at: https://try.jupyter.org.
Basic Python code and plotting
The box below (known as a code cell) contains the Python code to plot $y=x^2$ over the range [0,5]. The blue comments preceded by # explain what the code does.
To run the code:
- Click on the cell to select it.
- Press SHIFT+ENTER on your keyboard or press the play button in the toolbar above.
A full tutorial for using the notebook interface is available here.
Typing [shift] + [enter] will execute the cell and give you the output in a new line, labeled Out[1] (the numbering increases each time you execute a cell).
Try it! Add a cell with the plus button, enter some operations, and [shift] + [enter] to execute.
# Import matplotlib (plotting) and numpy (numerical arrays).
# This enables their use in the Notebook.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
# Create an array of 30 values for x equally spaced from 0 to 5.
x = np.linspace(0, 5, 30)
y = x**2
# Plot y versus x
fig, ax = plt.subplots(nrows=1, ncols=1)
ax.plot(x, y, color='red')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('A simple graph of $y=x^2$');
Above, you should see a plot of $y=x^2$.
You can edit this code and re-run it. For example, try replacing y = x**2 with y=np.sin(x). For a list of valid functions, see the NumPy Reference Manual. You can also update the plot title and axis labels.
Text in the plot as well as narrative text in the notebook can contain equations that are formatted using LATEX. To edit text written in LATEX, double click on the text or press ENTER when the text is selected.
More advanced plotting
This example uses the the standard ARPS equation to estimate the decline in oil or gas production from an oil well in North Dakota.
This example uses several Python libraries that are central to data analysis in Python: Pandas and SciPy. These libraries have functions we can use that save us time and ensure the code is consistent and replicable.
# Import pandas (DataFrames), SciPy (optimization functions), and matplotlib (plotting).
import pandas as pd
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
%matplotlib inline
# Creating some functions we can use to calcuate the hyperbolic curve and initial max production level
def hyperbolic_equation(t, qi, b, di):
return qi/((1.0+b*di*t)**(1.0/b))
def get_max_initial_production(df, number_first_months, variable_column, date_column):
df=df.sort_values(by=date_column)
df_beginning_production=df.head(number_first_months)
return df_beginning_production[variable_column].max()
# Reading the data into Python and saving it as a Pandas DataFrame
file_path='data/Decline Curve Analysis Example from Bakken.csv'
desired_product_type='Oil' # or 'Gas'
df=pd.read_csv(file_path)
df['ReportDate']=pd.to_datetime(df['ReportDate'])
# Evaluating the decline curve and saving it as a column in the DataFrame called "Hyperbolic Predicted"
qi=get_max_initial_production(df, 5, desired_product_type, 'ReportDate')
popt_hyp, pcov_hyp=curve_fit(hyperbolic_equation, df['Days_Online'],
df[desired_product_type],bounds=(0, [qi,2,20]))
df.loc[:,'Hyperbolic_Predicted']=hyperbolic_equation(df['Days_Online'], *popt_hyp)
# Plotting the actual and predicted production values
df.plot(x='Days_Online', y=[desired_product_type, "Hyperbolic_Predicted"],
title=f"Decline curve for {desired_product_type} Production")
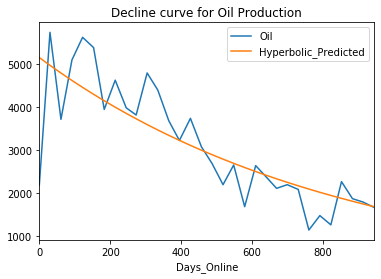
Change the desired product type to ‘Gas’ and rerun the example. Note how the values and even the title change.
Summary
In this tutorial, you were introduced to the Jupyter Notebook environment. Specifically, you learned:
- How to open the Jupyter notebook
- The difference between code cells and markdown cells
- How to execute cells with [shift] + [enter]
Next steps
It is also possible to run a notebook in the cloud, without installing the software.